基于视觉定位跟踪的大型机械部件数字化对接关键技术研究—谭启蒙 北京邮电大学 201204
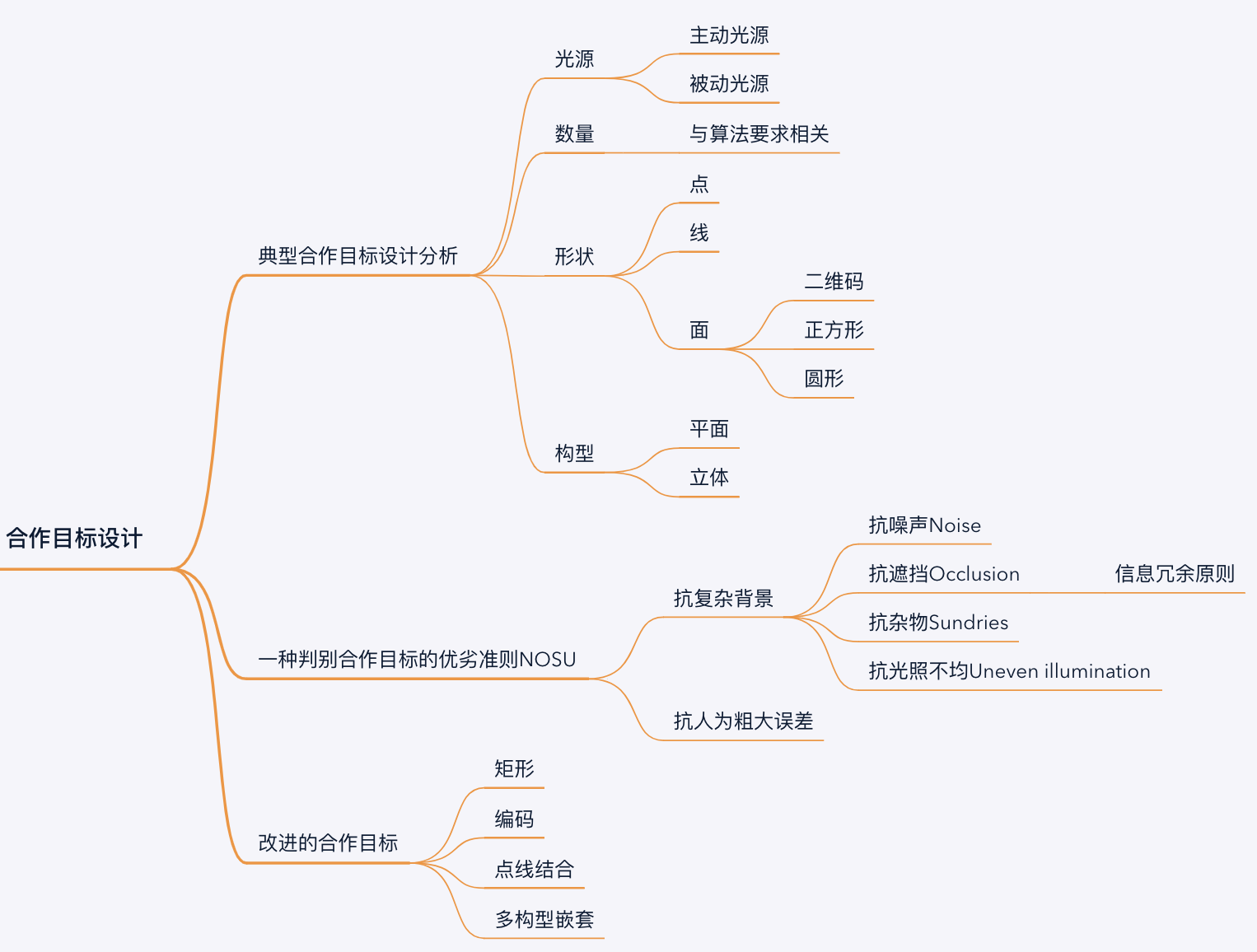
1.特征标志点规划布局设计
(1)全场控制点:均匀分布在装配现场之中,一方面用于建立装配现场中的全局坐标系;另一方面用于确定各个测量坐标系与全局坐标系之间的转换关系;
(2)拼接标志点:用于实现各个测量坐标系之间关系的转换;根据部件外形特征变化设置拼接标志点
(3)位姿控制点:用于建立各个大部件的局部坐标系与CAD设计模型坐标系之间的转换关系
(4)点集内的布局参数:1.点的个数 2.基准点的坐标 3.同一坐标系下各标志点与基准点之间的坐标差值
2.标志点规划布局的约束条件:
(1)曲率特征加权质心点约束
曲率特征是3D测量空间自身所固有的属性,与外界因素无关,因此,曲率特征分布将直接决定着标志点规划布局的疏密程度。假设存在一组标志点集,其中每个标志点处的主曲率设为k1,k2,且该点处的高斯曲率和平均曲率分别设定为k_gas,k_avg,将各标志点处的曲率特征作为求解质心坐标的权重系数,加权质心点位置会明显靠近于曲率变化明显点区域。基于刚体运动学原理,需要将标志点集视为刚体,而具有剧烈曲率变化的标志点所在位置对于坐标转换精度的影响更为显著,这就需要在曲率变化明显的区域布置相对较多的标志点,以保证坐标转换精度。
(2)坐标转换误差的平方和最小约束
根据最小二乘法基本原理可知,要获得最优解是基于所有计算的转换点,使得全部转换点的坐标转换误差的平方和最小。
(3)测试点的绝对误差指标最小约束
使用坐标值误差法、均方根法和相对欧式距离误差法对坐标转换精度进行评定。
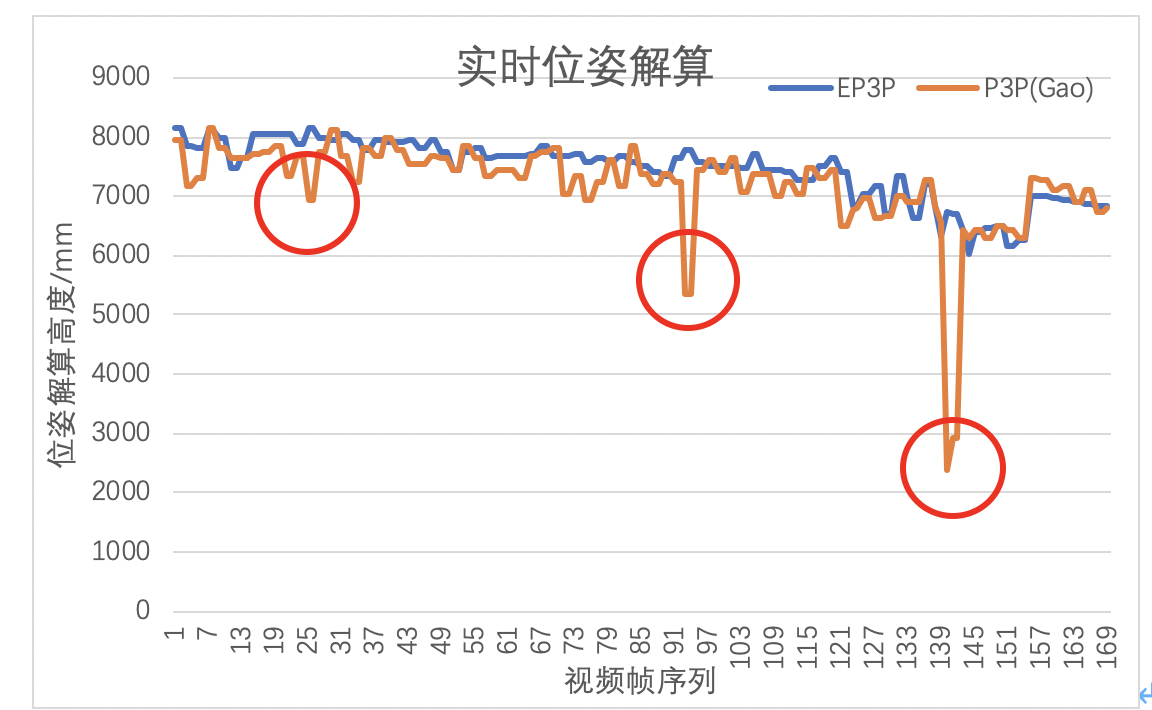
基于立体视觉的运动刚体位姿测量方法研究 —杨卫 哈尔滨工业大学 200906
1.特征点的布局优化
提出了基于2-范数的姿态误差表示方法,根据测量模型,给出了特征点布局相关量与姿态误差的数学关系;
结论:两个姿态矩阵R,Q间的差距的大小可以用它们差R-Q的2-范数(奇异值的最大值)表示,且R-Q且有一个为0的奇异值,另外两个奇异值相等;
2.优化布局方案
不同布局方式下的特征点,他们形成的向量矩阵Vm的广义逆的2-范数越小,系统测量误差对所求解姿态的影响也越小;